Contact
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms

Here you will find information on how to manage data during the active stage of a project. There are also tips on how to organise and describe data, and you can read about the considerations that need to be made in terms of information security, data protection and the principle of public access.
Organising, documenting, and describing data in a systematic manner right from the start of a project saves both time and energy, and, more importantly, improves the data quality. In addition, storing the data properly and securely will improve its integrity and further maximise its value.
When designing and planning a research project, there are a number of things that you need to take into consideration with regard to acquiring data. Addressing these issues early on in your project can save you time and effort later.
Depending on your research question, you may be working with primary data, reusing secondary data or a combination of both. Primary data is data that is collected or generated as part of your own research project. Secondary or third-party data is data that already exists and that has been collected or generated as part of someone else’s research project or activity. When it comes to reusing already existing data, you need to make sure you have permission to do so. Make certain you address all ethical, copyright, and rights management issues (e.g., intellectual property rights) that may apply to the data you will be working with.
It is important to consider both legal and ethical aspects of the data you intend to use. For instance, should you, as part of your research project, be collecting data containing personal or sensitive information, you need to ensure that you comply with data protection legislation and ethical guidelines (see section ‘Information security and data protection’ and Collecting persona data’ below for more information in this respect).
When you collect, generate, acquire and, eventually, start processing data, it can quickly become disorganised. To save time and prevent errors later on, you should decide on how you will organise and name files. Choosing a logical and consistent system allows you and others to locate, identify, and retrieve files quickly and accurately. Ideally, the best time to think about this is at the start of your project. Thus, file management is fundamental to good data management.
The Swedish National Data Service has several pages and guides about organising and structuring data:
Datasets and data files often go through a number of versions. Also, data may be processed by more than one person and over a longer period of time. To ensure the integrity of the data, it is important to keep track of and document the changes that are made. Version control is a way to track changes and revisions of a dataset.
Version control prevents errors, increases data quality and efficiency within a project, as well as facilitates reuse of the data at a later stage.
A good idea – especially when working in collaboration with others – is to document your file management system (i.e., folder structure, file and folder naming convention, file versioning, and choice of file format) in a supporting ReadMe file. It is recommended to place such a ReadMe file within the top-level folder of your project, where it can be found easily by everyone involved. Note: make sure to update the ReadMe file upon changes to the file management system.
There are a number of ways that version control can be managed, e.g. using file naming, version control tables or version control systems.
Using a revision numbering system (e.g., v01 for the first version, v02 for the second, etc.) to track changes to a file (example: 2020-07-28_ProjA_DMP_v01.docx, 2020-08-28_ProjA_DMP_v02.docx) and/or using initials (e.g., John Doe, JD) to identify who has made the changes (example: 2020-08-28_ProjA_DMP_v02_JD.docx).
More detailed information about file versioning can be found in:
Version control tables are included within the document itself and contain information such as version, date of change, name of person who made the change, and the nature and purpose of the change.
Version control systems are automated systems that monitor access and log changes made to a file. Examples of version control systems are git or Subversion.
Data that has been correctly documented and annotated will have significant ongoing value and can continue to have an impact long after your research project has been completed. Thoroughly and accurately describing and attributing the data will help you, your future you, your collaborators, and others find, understand, validate, and reuse it. Start describing and annotating the data early on while the required information is available).
Metadata is information about the data and one of the most important aspects of research data management. Metadata explains the context behind the structure and content of the data. It is used to describe and characterise elements of the data itself and should answer questions such as:
Ideally, you should describe and annotate metadata at different levels: project level, file/dataset level and data item/variable level.
Include information regarding the aim and research question of a research project. Document what data is collected, generated, and/or acquired and how it was done. Provide details on the type (e.g., observation, experiment) and nature (e.g., numerical, textual, audio, video) of the data. Explain any abbreviations used.
Include content, title, creator, date, format, version, data structure, and file relations in your documentation. Describe tools and abbreviations.
Document variables and values, field names, units of measurements, classifications as well as any code written and abbreviations used.
There are different ways in which you can document data. Certain metadata about a file or data may be embedded within the data or document itself, while some may be recorded in a separate, supporting document, such as a “ReadMe” text file. In any case, make sure such metadata or files are updated if the file or data is changed.
Applying a metadata standard when describing and annotating the data makes it easier to identify the data. It also makes comparing and combining data from different research projects easier. Making use of a metadata standard allows for a more structured description and annotation of the data and, as such, enables the metadata to be machine-readable.
Many research communities have agreed upon vocabularies and models for how to describe data. Make sure to use a community metadata standard where such is in place.
Structured and standardised (and thus machine-readable) metadata is important for making your data FAIR (Findable, Accessible, Interoperable, and Reusable) manner.
Read more about FAIR data and metadata:
In addition to creating metadata for the data itself is it also important to document and record all the actions and steps taken while creating, processing, and analysing the data (i.e., your workflow, see below).
Doing so ensures that the data can be verified, and that your research results can be validated and reproduced. If you develop computer code as part of your research activity, the code is an essential part of the research process and you should make sure it is documented, preserved, and shared.
Documenting experiments, field sampling, laboratory analyses, data processing and statistical analyses during the work is a good basis for well-written metadata and is necessary to make research reproducible. There are many tools and aids that can be useful for documenting processes and workflows, for example:
Read more in our guide: How to store and back up scientific data at SLU.
The purpose of information security and data protection legislation is to protect intellectual property rights, commercial interests and the security of personal or sensitive information. SLU’s data management policy stresses the importance of information security and states that data producers must ensure that research and environmental monitoring and assessment data are protected and classified for information security.
Ensuring that only authorised people have access to read and edit data is essential for keeping it protected. In order to decide how to properly safeguard data, you need to classify the information and data according to SLU’s three information security aspects confidentiality, integrity, and availability.
If you are going to collect personal data, you need to make sure you comply with data protection legislation. Before collecting and processing such data, make sure you read the information on the SLU data protection web page. This contains both a Quick guide to data protection in research and a more extensive Data protection manual. Questions can be sent to the SLU data protection function at dataskydd@slu.se.
Material produced as part of research as well as environmental monitoring and assessment activities carried out at SLU is the property of SLU. As SLU is a public institution, such material becomes official records/documents to which the public is guaranteed access under the Freedom of the Press Act. This means that anyone can request access to the material, even during the active stages of a project (e.g., data collection).
Public requests may in some cases be denied. Valid reasons to restrict access may be, for instance, that data contains personal or sensitive information or information pertaining to protected species.
Note that working material, such as draft documents, notes or preliminary processed material, are generally not considered official documents, as long as they are not shared outside SLU.
Research material that has the status of an official record needs to be managed according to the same principles as other official records. That means such documents have to be accessible and in good order so they can be released to the public upon request. They also have to be archived and preserved for the future.
This page is part of our introduction to data management. It covers the most common aspects of data management and includes best practice strategies, training resources and tips on data management tools. It is organised according to the data lifecycle (see below), a conceptual model that illustrates the different stages of data management.
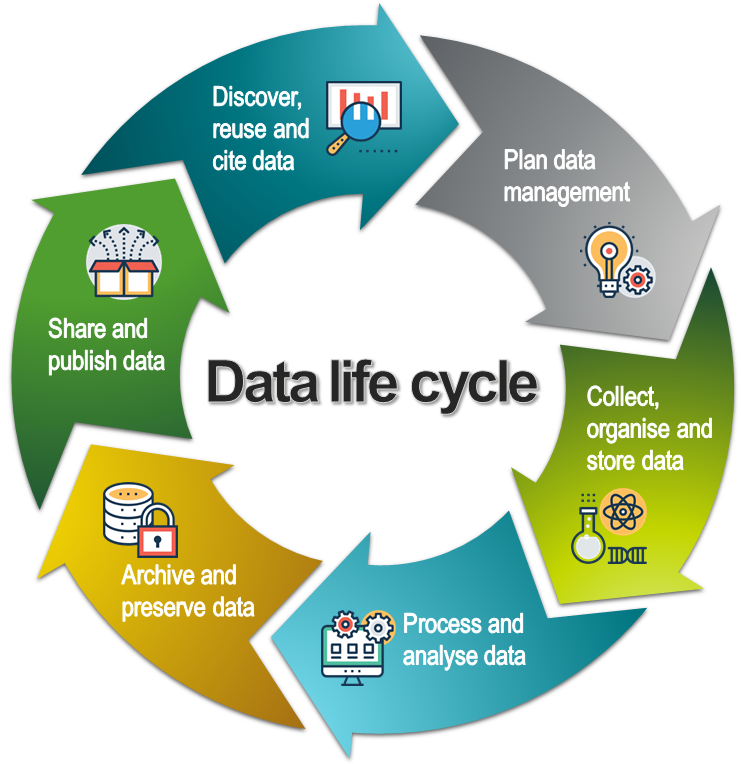
The data life cycle model. CC BY SLU Data Management Support. All icons in the life cycle and on the pages are made by Prosymbols from www.flaticon.com.
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms