Contact
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms

SLU’s data management policy states that data from research, as well as environmental monitoring and assessment, should be made available as openly as possible. This page provides information on why and how to share data, as well as guidance on choosing the right data-sharing strategy.
Sweden, like many other countries, is adopting the principles of open science. Open science is about making science more open, transparent, and inclusive as well as promoting innovation, knowledge transfer, and increase insight into the scientific process.
Open access to scientific publications and open access to research data are the two most important pillars of open science. Open access to research data means that data from research is openly and freely available online. Open data is also a central part of SLU's data management policy, which states that data from research and environmental monitoring and assessment should be published:
In addition, there is a growing demand from research funders and publishers that research data should be published and made openly available (see the end of this page for more details).
Data can be shared directly from the author, via peer-to-peer sharing, or by data publishing.
Data publishing can mean making data publicly available and discoverable via depositing it in a data repository, publishing a paper in a data journal, or publishing an article in a journal together with data as supplemental material.
Publishing data via a data repository can either mean depositing both data and metadata (i.e., a description of the data) or only metadata. Depositing data and/or metadata in a data repository allows for it to be discoverable. Data repositories can be specific for disciplines, domains, or institutions, or be more general.
In general, data repositories provide a persistent identifier (PID) in connection with the deposition of data and metadata. In some repositories, it is possible to publish with an embargo, i.e., deposit data and make them discoverable but not make the data openly available for a limited period of time.
Data papers, or data articles, focus on scientific data, allowing you to describe tools, methods, and processes used to acquire the data. The actual data (or metadata), however, is often deposited at a data repository (see above) and linked from the data paper. Data papers are peer-reviewed and citable.
There are dedicated data journals that publish both data papers and data. They seek to promote recognition for data creation, increase the reuse of data, improve the transparency of scientific methods and results, support good data management practices, and provide an accessible and permanent route to data.
Until recently, the general way of sharing data was as supplementary material to a peer-reviewed article published in a scientific journal. Sharing data as supplementary material could mean that journals and publishers keep the data behind a subscription wall and claim copyright over the data. Moreover, data may not be in a user-friendly format or functional for computer processing.
A growing number of journals and publishers require that data underlying a publication are openly accessible and linked from the article. Authors are asked to state where the data can be found and under what conditions it can be used (and, if not, why). Such statements in publications are known as data availability statements.
To link data to a publication you need a persistent identifier, such as a Digital Object Identifier (DOI). To get such an identifier (which can be included in your publication’s data availability statement), you will need to deposit the data or metadata at a data repository. Read more about data repositories below.
When it comes to general-purpose data repositories, DMS recommends the Swedish National Data Service (SND). Read more on our page about Publishing data via the Swedish National Data Service. We can also help you identify other suitable data repositories and assist you in preparing data for publication elsewhere. At re3data.org you can find a comprehensive list of both generic and discipline-specific repositories. You can also visit Discover, reuse, and cite data for several websites that may help you in identifying an appropriate repository.
Within many research domains, there are recognised and commonly used disciplinary data repositories. Sometimes journal publishers have specific requirements or recommendations, see for example Springer Nature’s list of recommended repositories.
When choosing a repository:
Please note that while you can make data available in open data repositories, research data must still be archived at SLU. Visit Archive and preserve data for more information.
Independent of which way data are shared, it is best practice to properly prepare the data before sharing and when doing so several issues need to be considered and addressed. For example, you need tidy files in sustainable formats with appropriate documentation and metadata to ensure that data can be discovered, accessed, understood, and reused in the future.
Several legal, ethical, and commercial issues need to be anticipated and addressed before sharing data. It is important to stress that it may not be possible to publish data openly if the data contains one or more of the following:
However, you may still publish the data, but not openly. For example, by publishing metadata (description of the data) at a data repository with information on how to get hold of the actual data.
As a rule, material (such as data) produced as part of research as well as environmental monitoring and assessment activities carried out at SLU are considered official records/documents. Therefore access to such must be granted on request unless there is a confidentiality provision according to the Public Access to Information and Secrecy Act. Such a request can be met by either allowing the enquirer to view or obtain the data on site or by providing a copy (depending on the circumstances).
To enable data reuse, it must be clear what others can do with the data you share. Licenses state the conditions according to which reuse is allowed: whether attribution is required (i.e., citation), how work resulting from the data can be shared further, and whether commercial use is permitted.
The SLU Data management policy requires that data are released with as few restrictions as possible.
Commonly used standard and open licences for data include Creative Commons and Open Data Commons licences. DIGG, the Swedish agency for digital government, has developed recommendations for the use of open licenses (in Swedish only). They recommend that data be published with a PDM (Public Domain Mark) or CC0 mark unless data are protected by copyright or database rights, then CC BY or equivalent should be used.
For something to fall under copyright protection, it must be the “result of personal intellectual creativity” and of “original and unique” character. In general, research data is not copyrightable. Research data can though, in some cases, fall under copyright protection if it contains copyrightable work (e.g., literary text, computer code, or works of art).
For large compilations of research data the database right may be applicable. The database right is comparable to but distinct from copyright, and its purpose is to recognise the investment made in compiling a database. It, however, does not involve the "creative" aspect required in copyright. In copyright, the rights holder is the creator (e.g., an author), while in the database right the rights holder is the organisation that made the economic investment to enable the compilation (e.g., a university).
Persistent identifiers (PIDs) are long-lasting references used for identifying datasets, for searching, retrieving, and linking or connecting data. In other words, they allow data to be findable and citable.
Several types of PIDs exist, such as DOI (Digital Object Identifier), Handle, URN, Ark, PURL. It does not really matter what kind of PID you use, though DOI is currently the most widespread
In order to obtain a PID for the data you intend to share, you will need to publish the data and/or its metadata in a data repository (see above).
Remember to include your affiliation in the metadata publishing data. Follow the instructions issued by SLU on how to correctly state your SLU affiliation when publishing
According to SLU's data management policy, data from research and environmental monitoring and assessment at SLU must be as openly available as possible, with as few restrictions as possible.
More and more funders mandate or strongly encourage making data as openly available as possible. Read more about the recommendations and requirements from some of the major funders:
This page is part of our introduction to data management. It covers the most common aspects of data management and includes best practice strategies, training resources and tips on data management tools. It is organised according to the data lifecycle (see below), a conceptual model that illustrates the different stages of data management.
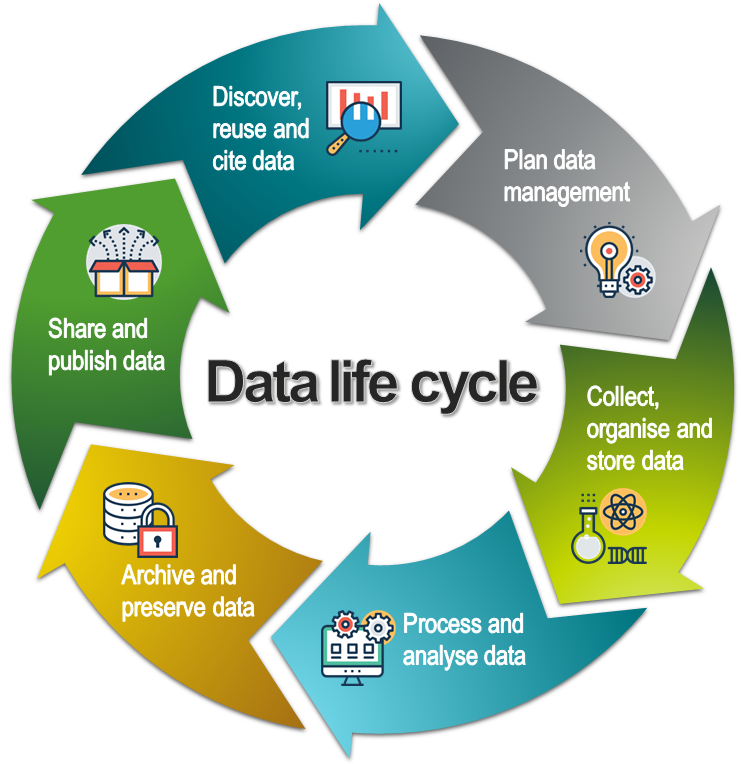
The data life cycle model. CC BY SLU Data Management Support. All icons in the life cycle and on the pages are made by Prosymbols from www.flaticon.com.
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms