Contact
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms

Here you can find information on how to find published data and factors to consider when re-using existing data collected by others.
Reusing existing datasets can avoid unnecessary duplication, inspire new research, and allow datasets from different studies or disciplines to be integrated. Many funders require you to investigate whether data already exists that can be used for your research question before you collect new data.
There are many ways to discover, search, and find data. Some examples, including a selection of search services and data repositories, are listed on the SLU University Library’s page Find research data and environmental monitoring data
Before using data that you have not collected yourself, you have a responsibility to respect the rights that may be held by other people or organisations. Therefore, check the terms and conditions of access and use, make sure that any licence granted by the author, organisation, government agency, etc. is appropriate for your purposes, and make sure that you obtain any necessary permissions or consents.
You also need to assess the quality of the data, its reliability, validity, etc. The following questions can be used as a starting point for quality checking the data:
When using secondary data, you should keep sufficiently detailed documentation about data and methods to enable other researchers to locate the original data and reproduce and validate your findings.
Make sure to address the following questions when documenting your reuse of secondary data:
When reusing or referencing data, you should cite the dataset in the same way as you would cite a scientific article. Correct citation of data is recognised as one of the key practices leading to the recognition of data as primary scientific output in its own right.
Styles and formats for citing data vary in the same way as article citation styles and formats vary. At SLU, referencing is done according to the Harvard system. According to this system, a data citation is written as follows:
Last name, Initial of first name. Name of institution (Year). Title. Data archive/publisher. Version no. Persistent link.
Example (in the reference list):
Snäll, T. & Mair, L. (2018). Species distribution modelling data for Phellinus ferrugineofuscus. Swedish National Data Service. Version1.0.
https://doi.org/10.5879/ECDS/2017-03-23.1/1
Example (in-text citation):
(Snäll et al. 2018)
If you are having trouble citing data correctly, you can try using the DOI Citation Formatter to automatically extract metadata from a DOI (digital object identifier) and generate a complete citation in a variety of citation styles.
This page is part of our introduction to data management. It covers the most common aspects of data management and includes best practice strategies, training resources and tips on data management tools. It is organised according to the data lifecycle (see below), a conceptual model that illustrates the different stages of data management.
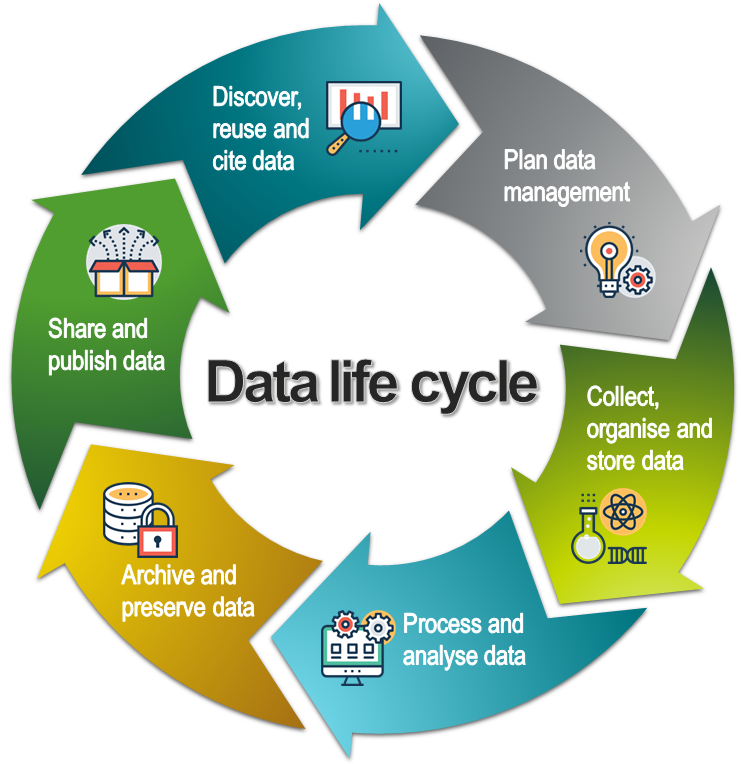
The data life cycle model. CC BY SLU Data Management Support. All icons in the life cycle and on the pages are made by Prosymbols from www.flaticon.com.
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms