Contact
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms

On this page you can read about the difference between raw and processed data, how version control can help you avoid errors and improve the quality of the data you work with, and how to handle personal data and sensitive information in research and environmental monitoring and assessment projects.
It is important to understand the difference between raw and processed data. Raw data is the original source data. It usually needs to be processed (i.e. prepared) prior to analysis. Data processing can include actions such as checking, organising, cleaning, transforming and subsetting the data.
To ensure the integrity and security of the data and to avoid data loss, it is essential that a copy of the raw data is made (preferably as a read-only version) and stored securely. This master copy of the raw data must not be altered and should be kept separate from the processed data.
When you are processing the data, you should record what you do: the steps you go through and the changes you are making. Keeping a log of your processing will allow you to review what you have done and repeat or re-do the processing if you want to change some step or procedure. It will also allow you, or someone else, to recreate a specific version of the data, for example to replicate your analysis or verify your findings.
Once you have finished processing and analysing the data, make sure to save a copy in a format that can be archived and preserved. Computer programmes used for processing or analysis often allow you to export and save versions of the data in different formats. For help with choosing a suitable format for your data, please visit the SND page 'Choosing a file format'.
Data that has been correctly documented and annotated will have significant ongoing value and can continue to have an impact long after your research project has been completed. Ideally, you should describe your data at different levels: project level, file/dataset level and data item/variable level.
Datasets and data files often go through a number of changes and exist in different versions. To ensure the integrity of the data and avoid confusion, it is important to keep track of these versions. Version control is a way to track changes and revisions of a dataset.
Data containing personal or sensitive information must be handled in accordance with data protection, freedom of information, and archives legislation.
Personal data is any type of information that can be used to identify a specific living individual. An individual may be identified directly by their name, address, telephone number, photography, voice, or some other unique personal characteristic, found alone or in combination. Indirect identification of an individual may occur when information is combined. For example, knowing someone’s age and place of work, or height and postal code may make it possible to identify a specific individual, even if their name is not revealed.
Sensitive personal data is e.g. data revealing racial or ethnic origin, political opinions, religious or philosophical beliefs, and sexual orientation. Sensitive data can also refer to non-human data, such as geospatial data that reveals the location of protected species or other confidential objects, or confidential information.
One way to make sure personal, or sensitive, information is not revealed accidentally is to anonymise or pseudonymised the data by removing or replacing the identifying features. It may also be possible to de-sensitise the data in different ways (more information below).
Anonymisation, or de-identification, is the process of removing all information that may lead to an individual being identified. When data has been anonymised it should be impossible for anyone to identify the relevant individual. If you need to be able to identify individuals or objects during and after your project, for follow-up purposes for instance, data should be pseudonymised rather than anonymised.
Pseudonymisation is when personal information is processed so that the data no longer can be linked to a specific individual without the use of additional information. The process often involves substituting identifiers (e.g., name or social security number) with other values or codes. The original value and the new code are recorded in a list or similar, and this code key can then be used to de-code the pseudonymised information if needed. It is important to ensure the additional information or code key is not stored together with the data but in a separate location, safely with controlled and limited access.
If you are working with sensitive data you may need to mask or distort it in order to de-sensitise the data before making it available. As examples, approximations of data values for geographical coordinates could be used rendering identification of the location of sensitive subjects/objects impossible without access to the original data, birth dates could be replaced by age rages, sector or occupation could be used instead of specific roles or titles, etc. What you need to do depends on the data you are working on. Contact DMS for further guidance.
If you are going to work with personal data you need to make sure you comply with data protection legislation.
This page is part of our introduction to data management. It covers the most common aspects of data management and includes best practice strategies, training resources and tips on data management tools. It is organised according to the data lifecycle (see below), a conceptual model that illustrates the different stages of data management.
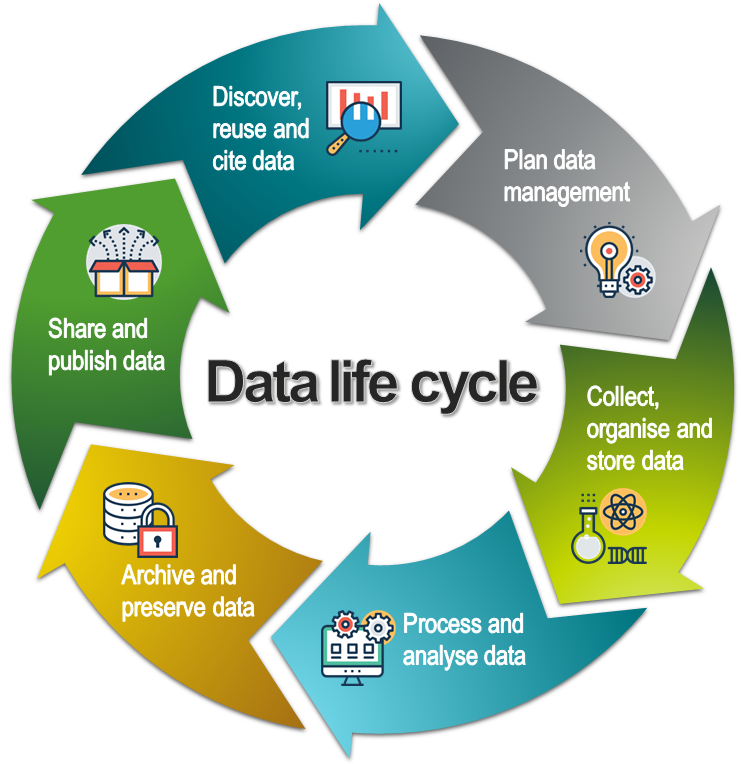
The data life cycle model. CC BY SLU Data Management Support. All icons in the life cycle and on the pages are made by Prosymbols from www.flaticon.com.
Data Management Support (DMS)
dms@slu.se | www.slu.se/dms